Regressionsanalys. Regressionsanalys - en statistisk metod för att studera en slumpvariabels beroende av variabler Regressionsanalys steg för steg
Vad är regression?
Betrakta två kontinuerliga variabler x=(xl, x2, .., x n), y=(yi, y2, ..., y n).
Låt oss placera punkterna på en 2D-spridningsplot och säga att vi har linjärt förhållande om data approximeras med en rät linje.
Om vi antar det y beror på x, och ändringarna i y orsakas av förändringar i x, kan vi definiera en regressionslinje (regression y på x), som bäst beskriver det linjära sambandet mellan dessa två variabler.
Den statistiska användningen av ordet "regression" kommer från ett fenomen som kallas regression till medelvärdet, tillskrivet Sir Francis Galton (1889).
Han visade att medan långa fäder tenderar att ha långa söner, är medellängden på söner mindre än för deras långa fäder. Den genomsnittliga längden på sönerna "föll tillbaka" och "flyttades tillbaka" till medellängden för alla fäder i befolkningen. Således har långa fäder i genomsnitt kortare (men fortfarande långa) söner, och korta fäder har längre (men fortfarande ganska korta) söner.
regressionslinje
Matematisk ekvation som utvärderar en enkel (parvis) linjär regressionslinje:
x kallas den oberoende variabeln eller prediktorn.
Yär den beroende eller svarsvariabeln. Detta är värdet vi förväntar oss för y(i genomsnitt) om vi vet värdet x, dvs. är det förutsagda värdet y»
- a- gratis medlem (korsning) av utvärderingslinjen; detta värde Y, när x=0(Figur 1).
- b- lutning eller lutning för den beräknade linjen; det är det belopp med vilket Yökar i genomsnitt om vi ökar x för en enhet.
- a Och b kallas regressionskoefficienterna för den uppskattade linjen, även om denna term ofta endast används för b.
Parvis linjär regression kan utökas till att omfatta mer än en oberoende variabel; i detta fall är det känt som multipel regression.
Figur 1. Linjär regressionslinje som visar skärningspunkten mellan a och lutningen b (mängden ökning av Y när x ökar med en enhet)
Minsta kvadratiska metod
Vi utför regressionsanalys med hjälp av ett urval av observationer där a Och b- provuppskattningar av de sanna (allmänna) parametrarna, α och β , som bestämmer den linjära regressionslinjen i populationen (allmän population).
Den enklaste metoden för att bestämma koefficienterna a Och bär en minsta kvadratmetoden(MNK).
Passningen utvärderas genom att beakta residualerna (det vertikala avståndet för varje punkt från linjen, t.ex. residual = observerbar y- förutspått y, Ris. 2).
Linjen med bästa passform väljs så att summan av kvadraterna av resterna är minimal.

Ris. 2. Linjär regressionslinje med avbildade residualer (vertikala prickade linjer) för varje punkt.
Antaganden om linjär regression
Så för varje observerat värde är restvärdet lika med skillnaden och motsvarande förutsagda. Varje restvärde kan vara positiv eller negativ.
Du kan använda residualer för att testa följande antaganden bakom linjär regression:
- Residualerna är normalfördelade med noll medelvärde;
Om antagandena om linjäritet, normalitet och/eller konstant varians är tveksamma, kan vi transformera eller och beräkna en ny regressionslinje för vilken dessa antaganden är uppfyllda (t.ex. använd en logaritmisk transformation, etc.).
Onormala värden (outliers) och influenspunkter
En "inflytelserik" observation, om den utelämnas, ändrar en eller flera modellparameteruppskattningar (dvs. lutning eller skärning).
En extremvärde (en observation som strider mot de flesta av värdena i datamängden) kan vara en "inflytelserik" observation och kan väl detekteras visuellt när man tittar på en 2D-spridningsplot eller en plot av rester.
Både för extremvärden och för "inflytelserika" observationer (punkter) används modeller, både med deras inkludering och utan dem, var uppmärksam på förändringen i skattningen (regressionskoefficienter).
När du gör en analys, kasta inte bort extremvärden eller påverkanspunkter automatiskt, eftersom att bara ignorera dem kan påverka resultaten. Studera alltid orsakerna till dessa extremvärden och analysera dem.
Linjär regressionshypotes
Vid konstruktion av en linjär regression kontrolleras nollhypotesen att den allmänna lutningen för regressionslinjen β är lika med noll.
Om linjens lutning är noll finns det inget linjärt samband mellan och: förändringen påverkar inte
För att testa nollhypotesen att den sanna lutningen är noll kan du använda följande algoritm:
Beräkna teststatistiken lika med förhållandet , som följer en fördelning med frihetsgrader, där standardfelet för koefficienten

 ,
,
 - uppskattning av variansen av residualerna.
- uppskattning av variansen av residualerna.
Vanligtvis, om den uppnådda signifikansnivån är nollhypotesen förkastas.
![]()
var är den procentenhet av fördelningen med frihetsgrader som ger sannolikheten för ett tvåsidigt test
Detta är intervallet som innehåller den allmänna lutningen med en sannolikhet på 95 %.
För stora urval, låt oss säga att vi kan approximera med ett värde på 1,96 (det vill säga att teststatistiken tenderar att vara normalfördelad)
Utvärdering av kvaliteten på linjär regression: bestämningskoefficient R 2
På grund av det linjära sambandet och vi förväntar oss att det förändras allt eftersom
, och vi kallar detta den variation som beror på eller förklaras av regressionen. Den kvarvarande variationen bör vara så liten som möjligt.
Om så är fallet kommer det mesta av variationen att förklaras av regressionen, och punkterna kommer att ligga nära regressionslinjen, dvs. linjen passar data väl.
Andelen av den totala variansen som förklaras av regressionen kallas bestämningskoefficient, vanligtvis uttryckt i procent och betecknat R2(i parad linjär regression är detta värdet r2, kvadraten på korrelationskoefficienten), låter dig subjektivt bedöma kvaliteten på regressionsekvationen.
Skillnaden är den procentuella variansen som inte kan förklaras med regression.
Utan något formellt test att utvärdera, är vi tvungna att förlita oss på subjektiv bedömning för att bestämma kvaliteten på anpassningen av regressionslinjen.
Tillämpa en regressionslinje på en prognos
Du kan använda en regressionslinje för att förutsäga ett värde från ett värde inom det observerade intervallet (extrapolera aldrig utöver dessa gränser).
Vi förutsäger medelvärdet för observerbara värden som har ett visst värde genom att ersätta det värdet i regressionslinjeekvationen.
Så om vi förutsäger använder vi detta förutsagda värde och dess standardfel för att uppskatta konfidensintervallet för det sanna populationsmedelvärdet.
Genom att upprepa denna procedur för olika värden kan du bygga konfidensgränser för denna linje. Detta är ett band eller område som innehåller en sann linje, till exempel med en konfidensnivå på 95 %.
Enkla regressionsplaner
Enkla regressionsdesigner innehåller en kontinuerlig prediktor. Om det finns 3 fall med prediktorvärden P , såsom 7, 4 och 9, och designen inkluderar en första ordningens effekt P , kommer designmatrisen X att vara

och regressionsekvationen med P för X1 ser ut som
Y = b0 + b1 P
Om en enkel regressionsdesign innehåller en effekt av högre ordning på P, såsom en kvadratisk effekt, kommer värdena i kolumn X1 i designmatrisen att höjas till andra potens:

och ekvationen kommer att ta formen
Y = bO + bi P2
Sigma-begränsade och överparameteriserade kodningsmetoder gäller inte för enkla regressionsdesigner och andra designs som endast innehåller kontinuerliga prediktorer (eftersom det helt enkelt inte finns några kategoriska prediktorer). Oavsett vilken kodningsmetod som valts, ökas värdena för de kontinuerliga variablerna med lämplig effekt och används som värden för X-variablerna. I detta fall utförs ingen konvertering. Dessutom, när du beskriver regressionsplaner, kan du utelämna hänsyn till planmatrisen X och endast arbeta med regressionsekvationen.
Exempel: Enkel regressionsanalys
Det här exemplet använder uppgifterna i tabellen:

Ris. 3. Tabell över initiala data.
Uppgifterna bygger på en jämförelse av folkräkningarna 1960 och 1970 i 30 slumpmässigt utvalda län. Länsnamn representeras som observationsnamn. Information om varje variabel presenteras nedan:

Ris. 4. Variabel specifikationstabell.
Forskningsmål
För det här exemplet kommer korrelationen mellan fattigdomsgraden och den makt som förutsäger andelen familjer som ligger under fattigdomsgränsen att analyseras. Därför kommer vi att behandla variabel 3 (Pt_Poor ) som en beroende variabel.
Man kan lägga fram en hypotes: förändringen i befolkningen och andelen familjer som ligger under fattigdomsgränsen hänger ihop. Det verkar rimligt att förvänta sig att fattigdom leder till ett utflöde av befolkning, därför skulle det finnas en negativ korrelation mellan andelen människor under fattigdomsgränsen och befolkningsförändringen. Därför kommer vi att behandla variabel 1 (Pop_Chng ) som en prediktorvariabel.
Se Resultat
Regressionskoefficienter

Ris. 5. Regressionskoefficienter Pt_Poor på Pop_Chng.
Vid skärningspunkten mellan Pop_Chng-raden och Param. den icke-standardiserade koefficienten för regression av Pt_Poor på Pop_Chng är -0,40374 . Detta innebär att för varje minskning av befolkningen ökar fattigdomen med 0,40374. De övre och nedre (standard) 95 % konfidensgränserna för denna icke-standardiserade koefficient inkluderar inte noll, så regressionskoefficienten är signifikant på p-nivån<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
Fördelning av variabler
Korrelationskoefficienter kan bli betydligt över- eller underskattade om det finns stora extremvärden i data. Låt oss undersöka fördelningen av den beroende variabeln Pt_Poor per län. För att göra detta kommer vi att bygga ett histogram av variabeln Pt_Poor.

Ris. 6. Histogram för variabeln Pt_Poor.
Som du kan se skiljer sig fördelningen av denna variabel markant från normalfördelningen. Men även om även två län (de två högra kolumnerna) har en högre andel familjer som ligger under fattigdomsgränsen än förväntat i en normalfördelning, verkar de vara "inom intervallet".

Ris. 7. Histogram för variabeln Pt_Poor.
Denna bedömning är något subjektiv. Tumregeln är att extremvärden ska beaktas om en observation (eller observationer) inte faller inom intervallet (medelvärde ± 3 gånger standardavvikelsen). I det här fallet är det värt att upprepa analysen med och utan extremvärden för att säkerställa att de inte har en allvarlig effekt på korrelationen mellan medlemmar i befolkningen.
Scatterplot
Om en av hypoteserna a priori handlar om förhållandet mellan de givna variablerna, är det användbart att kontrollera det på plotten av motsvarande spridningsdiagram.

Ris. 8. Scatterplot.
Spridningsdiagrammet visar en tydlig negativ korrelation (-.65) mellan de två variablerna. Den visar också 95 % konfidensintervall för regressionslinjen, dvs med 95 % sannolikhet passerar regressionslinjen mellan de två streckade kurvorna.
Signifikanskriterier

Ris. 9. Tabell som innehåller signifikanskriterierna.
Testet för Pop_Chng-regressionskoefficienten bekräftar att Pop_Chng är starkt relaterat till Pt_Poor , p<.001 .
Resultat
Detta exempel visade hur man analyserar en enkel regressionsplan. En tolkning av icke-standardiserade och standardiserade regressionskoefficienter presenterades också. Vikten av att studera responsfördelningen för den beroende variabeln diskuteras och en teknik för att bestämma riktningen och styrkan av sambandet mellan prediktorn och den beroende variabeln demonstreras.
Modern statsvetenskap utgår från ståndpunkten om förhållandet mellan alla fenomen och processer i samhället. Det är omöjligt att förstå händelser och processer, förutsäga och hantera det politiska livets fenomen utan att studera de samband och beroenden som finns i samhällets politiska sfär. En av policyforskningens vanligaste uppgifter är att studera sambandet mellan några observerbara variabler. En hel klass av statistiska analysmetoder, förenade med det vanliga namnet "regressionsanalys" (eller, som det också kallas, "korrelations-regressionsanalys"), hjälper till att lösa detta problem. Men om korrelationsanalys gör det möjligt att bedöma styrkan i sambandet mellan två variabler, är det med hjälp av regressionsanalys möjligt att bestämma typen av detta samband, för att förutsäga beroendet av värdet av en variabel på värdet av en annan variabel .
Låt oss först komma ihåg vad en korrelation är. Korrelativ kallas det viktigaste specialfallet av statistiskt samband, vilket består i det faktum att lika värden på en variabel motsvarar olika medelvärden annan. Med en förändring av värdet på attributet x ändras naturligt medelvärdet av attributet y, medan i varje enskilt fall värdet på attributet på(med olika sannolikheter) kan anta många olika värden.
Utseendet på termen "korrelation" i statistik (och statsvetenskap lockar till att uppnå statistik för att lösa sina problem, som därför är en disciplin relaterad till statsvetenskap) är associerad med namnet på den engelske biologen och statistikern Francis Galton, som friade på 1800-talet. teoretiska grunder för korrelations-regressionsanalys. Termen "korrelation" inom vetenskapen var känd tidigare. I synnerhet inom paleontologin på 1700-talet. den tillämpades av den franske vetenskapsmannen Georges Cuvier. Han införde den så kallade korrelationslagen, med hjälp av vilken det, enligt resterna av djur som hittats vid utgrävningar, var möjligt att återställa deras utseende.
Det finns en välkänd historia förknippad med namnet på denna vetenskapsman och hans lag om korrelation. Så, på dagarna av en universitetssemester, drog studenter som bestämde sig för att spela en berömd professor ett spratt ett getskinn med horn och hovar över en student. Han klättrade in i fönstret till Cuviers sovrum och ropade: "Jag äter dig." Professorn vaknade, tittade på siluetten och svarade: ”Om du har horn och hovar, då är du en växtätare och kan inte äta mig. Och för okunnighet om korrelationslagen får du en tvåa. Han vände sig om och somnade. Ett skämt är ett skämt, men i det här exemplet ser vi ett specialfall av att använda multipel korrelations-regressionsanalys. Här härledde professorn, baserat på kunskapen om värdena för de två observerade egenskaperna (närvaron av horn och hovar), baserat på korrelationslagen, medelvärdet för den tredje egenskapen (klassen som detta djur tillhör är en växtätare). I det här fallet talar vi inte om det specifika värdet av denna variabel (dvs detta djur kan anta olika värden på en nominell skala - det kan vara en get, en bagge eller en tjur ...).
Låt oss nu gå vidare till termen "regression". Strängt taget hänger det inte ihop med innebörden av de statistiska problem som löses med hjälp av denna metod. En förklaring av begreppet kan endast ges på grundval av kunskap om historien om utvecklingen av metoder för att studera sambanden mellan egenskaper. Ett av de första exemplen på studier av detta slag var statistikerna F. Galton och K. Pearsons arbete, som försökte hitta ett mönster mellan fäders och deras barns tillväxt enligt två observerbara tecken (där X- fars längd och U- barns tillväxt). I sin studie bekräftade de den initiala hypotesen att långa fäder i genomsnitt uppfostrar medellånga barn. Samma princip gäller låga fäder och barn. Men om forskarna hade stannat där skulle deras verk aldrig ha nämnts i läroböcker om statistik. Forskarna hittade ett annat mönster inom den redan nämnda bekräftade hypotesen. De bevisade att mycket långa fäder producerar barn som är långa i genomsnitt, men inte särskilt olika i längd från barn vars fäder, även om de är över genomsnittet, inte skiljer sig mycket från medellängden. Detsamma gäller för fäder med mycket liten resning (som avviker från genomsnittet för den korta gruppen) - deras barn skilde sig i genomsnitt inte i längd från jämnåriga vars fäder helt enkelt var korta. De kallade funktionen som beskriver denna regelbundenhet regressionsfunktion. Efter denna studie började alla ekvationer som beskriver liknande funktioner och konstruerade på liknande sätt att kallas regressionsekvationer.
Regressionsanalys är en av metoderna för multivariat statistisk dataanalys, som kombinerar en uppsättning statistiska tekniker utformade för att studera eller modellera samband mellan en beroende och flera (eller en) oberoende variabler. Den beroende variabeln, enligt traditionen accepterad i statistiken, kallas respons och betecknas som V De oberoende variablerna kallas prediktorer och betecknas som x. Under analysens gång kommer vissa variabler att vara svagt relaterade till svaret och kommer så småningom att uteslutas från analysen. De återstående variablerna förknippade med den beroende kan också kallas faktorer.
Regressionsanalys gör det möjligt att förutsäga värdena för en eller flera variabler beroende på en annan variabel (till exempel benägenheten för okonventionellt politiskt beteende beroende på utbildningsnivå) eller flera variabler. Det beräknas på PC. För att sammanställa en regressionsekvation som låter dig mäta graden av beroende av den kontrollerade funktionen på faktorn, är det nödvändigt att involvera professionella matematiker-programmerare. Regressionsanalys kan ge en ovärderlig tjänst för att bygga prediktiva modeller för utvecklingen av en politisk situation, bedöma orsakerna till sociala spänningar och genomföra teoretiska experiment. Regressionsanalys används aktivt för att studera inverkan på medborgarnas valbeteende av ett antal sociodemografiska parametrar: kön, ålder, yrke, bostadsort, nationalitet, nivå och art av inkomst.
I relation till regressionsanalys, begreppen oberoende Och beroende variabler. En oberoende variabel är en variabel som förklarar eller orsakar en förändring i en annan variabel. En beroende variabel är en variabel vars värde förklaras av den första variabelns inflytande. Till exempel i presidentvalet 2004 var de avgörande faktorerna, dvs. oberoende variabler var indikatorer som stabilisering av den ekonomiska situationen för befolkningen i landet, graden av popularitet för kandidater och faktorn tjänstgöring. I det här fallet kan andelen avgivna röster för kandidater betraktas som en beroende variabel. På liknande sätt, i paret av variabler "väljarens ålder" och "nivå av valaktivitet", är den första oberoende, den andra är beroende.
Regressionsanalys låter dig lösa följande problem:
- 1) fastställa själva faktumet av närvaron eller frånvaron av ett statistiskt signifikant samband mellan Ci x;
- 2) bygga de bästa (i statistisk mening) uppskattningarna av regressionsfunktionen;
- 3) enligt de givna värdena X skapa en förutsägelse för det okända På
- 4) utvärdera den specifika vikten av påverkan av varje faktor X på På och följaktligen utesluta obetydliga egenskaper från modellen;
- 5) genom att identifiera orsakssamband mellan variabler, delvis hantera värdena för P genom att justera värdena för förklarande variabler x.
Regressionsanalys är förknippat med behovet av att välja ömsesidigt oberoende variabler som påverkar värdet på den indikator som studeras, bestämma formen på regressionsekvationen och utvärdera parametrar med hjälp av statistiska metoder för bearbetning av primär sociologisk data. Denna typ av analys är baserad på idén om förhållandets form, riktning och närhet (densitet). Skilja på ångbastu Och multipel regression beroende på antalet studerade funktioner. I praktiken utförs regressionsanalys vanligtvis i samband med korrelationsanalys. Regressions ekvation beskriver ett numeriskt samband mellan kvantiteter, uttryckt som en tendens för en variabel att öka eller minska medan en annan ökar eller minskar. Samtidigt, razl och h a yut l glasera Och icke-linjär regression. Vid beskrivning av politiska processer återfinns båda varianterna av regression lika.
Scatterplot för fördelning av ömsesidigt beroende av intressen i politiska artiklar ( U) och utbildning av respondenterna (X)är en linjär regression (fig. 30).
Ris. trettio.
Scatterplot för fördelning av nivån på valaktivitet ( U) och respondentens ålder (A) (villkorligt exempel) är en icke-linjär regression (Fig. 31).

Ris. 31.
För att beskriva förhållandet mellan två egenskaper (A "och Y) i en parad regressionsmodell används en linjär ekvation
![]()
där a, är ett slumpmässigt värde på felet i ekvationen med variation av egenskaper, dvs. ekvationens avvikelse från "linjäritet".
För att utvärdera koefficienterna men Och b använd minsta kvadratmetoden, som förutsätter att summan av de kvadrerade avvikelserna för varje punkt på spridningsdiagrammet från regressionslinjen ska vara minimal. Odds a h b kan beräknas med hjälp av ekvationssystemet: 
Metoden för uppskattning av minsta kvadrater ger sådana uppskattningar av koefficienterna men Och b, för vilken linjen går genom punkten med koordinater X Och y, de där. det finns ett samband på = yxa + b. Den grafiska representationen av regressionsekvationen kallas teoretisk regressionslinje. Med ett linjärt beroende representerar regressionskoefficienten på grafen tangenten för lutningen av den teoretiska regressionslinjen till x-axeln. Tecknet vid koefficienten visar anslutningens riktning. Om det är större än noll är sambandet direkt, om det är mindre är det omvänt.
Följande exempel från studien "Politisk Petersburg-2006" (Tabell 56) visar ett linjärt samband mellan medborgarnas uppfattning om graden av tillfredsställelse med sina liv i nuet och förväntningar på förändringar i livskvaliteten i framtiden. Kopplingen är direkt, linjär (den standardiserade regressionskoefficienten är 0,233, signifikansnivån är 0,000). I det här fallet är regressionskoefficienten inte hög, men den överskrider den nedre gränsen för den statistiskt signifikanta indikatorn (den nedre gränsen för kvadraten av den statistiskt signifikanta indikatorn för Pearson-koefficienten).
Tabell 56
Inverkan av medborgarnas livskvalitet i nuet på förväntningarna
(S:t Petersburg, 2006)
* Beroende variabel: "Hur tror du att ditt liv kommer att förändras under de kommande 2-3 åren?"
I det politiska livet beror värdet av den studerade variabeln oftast samtidigt på flera egenskaper. Till exempel påverkas nivån och arten av politisk aktivitet samtidigt av statens politiska regim, politiska traditioner, särdragen hos människors politiska beteende i ett visst område och respondentens sociala mikrogrupp, hans ålder, utbildning, inkomst nivå, politisk inriktning m.m. I det här fallet måste du använda ekvationen multipel regression, som har följande form:
där koefficient b.- partiell regressionskoefficient. Den visar bidraget från varje oberoende variabel för att bestämma värdena för den oberoende (utfalls)variabeln. Om den partiella regressionskoefficienten är nära 0, kan vi dra slutsatsen att det inte finns något direkt samband mellan de oberoende och beroende variablerna.
Beräkningen av en sådan modell kan utföras på en PC med hjälp av matrisalgebra. Multipel regression låter dig återspegla den multifaktoriella karaktären hos sociala band och förtydliga måttet på effekten av varje faktor individuellt och alla tillsammans på den resulterande egenskapen.
Koefficient betecknad b, kallas linjär regressionskoefficient och visar styrkan i sambandet mellan variationen av faktorattributet X och variation av den effektiva funktionen Y Denna koefficient mäter styrkan av sambandet i absoluta måttenheter för egenskaper. Emellertid kan närheten av korrelationen av egenskaper också uttryckas i termer av standardavvikelsen för den resulterande egenskapen (en sådan koefficient kallas korrelationskoefficienten). Till skillnad från regressionskoefficienten b Korrelationskoefficienten beror inte på de accepterade måttenheterna för egenskaper, och därför är den jämförbar för alla egenskaper. Vanligtvis anses kopplingen vara stark om /> 0,7, medel täthet - vid 0,5 g 0,5.
Den närmaste anknytningen är som bekant en funktionell koppling, då varje enskild värde Y kan unikt tilldelas värdet x. Således, ju närmare korrelationskoefficienten är 1, desto närmare är relationen en funktionell. Signifikansnivån för regressionsanalys bör inte överstiga 0,001.
Korrelationskoefficienten har länge ansetts som huvudindikatorn på hur nära förhållandet mellan funktioner är. Men senare blev bestämningskoefficienten en sådan indikator. Innebörden av denna koefficient är som följer - den återspeglar andelen av den totala variansen av den resulterande egenskapen På, förklaras av funktionens varians x. Den hittas genom att helt enkelt kvadrera korrelationskoefficienten (som ändras från 0 till 1) och i sin tur, för ett linjärt samband reflekterar andelen från 0 (0%) till 1 (100 %) karakteristiska värden Y, bestäms av värdena för attributet x. Det är inspelat som jag 2, och i de resulterande tabellerna för regressionsanalys i SPSS-paketet - utan en kvadrat.
Låt oss beteckna huvudproblemen med att konstruera den multipla regressionsekvationen.
- 1. Val av faktorer som ingår i regressionsekvationen. I detta skede sammanställer forskaren först en allmän lista över de huvudsakliga orsakerna som, enligt teorin, bestämmer fenomenet som studeras. Sedan måste han välja funktionerna i regressionsekvationen. Huvudurvalsregeln är att de faktorer som ingår i analysen ska korrelera så lite som möjligt med varandra; endast i detta fall är det möjligt att tillskriva ett visst faktorattribut ett kvantitativt mått på inflytande.
- 2. Välja formen för multipla regressionsekvationen(i praktiken används oftare linjär eller linjär-logaritmisk). Så för att använda multipel regression måste forskaren först bygga en hypotetisk modell av påverkan av flera oberoende variabler på den resulterande. För att de erhållna resultaten ska vara tillförlitliga är det nödvändigt att modellen exakt matchar den verkliga processen, d.v.s. relationen mellan variabler måste vara linjär, inte en enda signifikant oberoende variabel kan ignoreras, precis som inte en enda variabel som inte är direkt relaterad till den process som studeras kan inkluderas i analysen. Dessutom måste alla mätningar av variabler vara extremt exakta.
Från ovanstående beskrivning följer ett antal villkor för tillämpningen av denna metod, utan vilka det är omöjligt att gå vidare till proceduren för multipel regressionsanalys (MRA). Endast överensstämmelse med alla följande punkter gör att du kan utföra en regressionsanalys korrekt.
Regressionsanalys är en statistisk forskningsmetod som låter dig visa en parameters beroende av en eller flera oberoende variabler. Under före-datortiden var användningen ganska svår, särskilt när det gällde stora mängder data. Idag, efter att ha lärt dig hur man bygger en regression i Excel, kan du lösa komplexa statistiska problem på bara ett par minuter. Nedan finns specifika exempel från ekonomiområdet.
Typer av regression
Själva konceptet introducerades i matematiken 1886. Regression sker:
- linjär;
- parabolisk;
- kraft;
- exponentiell;
- hyperbolisk;
- demonstrativ;
- logaritmisk.
Exempel 1
Tänk på problemet med att bestämma antalet pensionerade teammedlemmars beroende av den genomsnittliga lönen vid 6 industriföretag.
En uppgift. På sex företag analyserade vi den genomsnittliga månadslönen och antalet anställda som slutat av egen vilja. I tabellform har vi:
Antalet personer som lämnade | Lön |
||
30 000 rubel |
|||
35 000 rubel |
|||
40 000 rubel |
|||
45 000 rubel |
|||
50 000 rubel |
|||
55 000 rubel |
|||
60 000 rubel |
För problemet med att bestämma antalet pensionerade arbetares beroende av medellönen vid 6 företag har regressionsmodellen formen av ekvationen Y = a 0 + a 1 x 1 +…+akxk , där xi är de påverkande variablerna , ai är regressionskoefficienterna, ak är antalet faktorer.
För denna uppgift är Y indikatorn på anställda som slutat, och den påverkande faktorn är lönen, som vi betecknar med X.
Använda funktionerna i kalkylarket "Excel"
Regressionsanalys i Excel måste föregås av applicering av inbyggda funktioner på tillgängliga tabelldata. Men för dessa ändamål är det bättre att använda det mycket användbara tillägget "Analysis Toolkit". För att aktivera det behöver du:
- från fliken "Arkiv", gå till avsnittet "Alternativ";
- i fönstret som öppnas, välj raden "Tillägg";
- klicka på "Go"-knappen längst ner, till höger om "Management"-raden;
- markera rutan bredvid namnet "Analyspaket" och bekräfta dina åtgärder genom att klicka på "OK".
Om allt är gjort korrekt visas den önskade knappen på höger sida av fliken Data, som ligger ovanför Excel-kalkylbladet.
i Excel
Nu när vi har alla nödvändiga virtuella verktyg till hands för att utföra ekonometriska beräkningar, kan vi börja lösa vårt problem. För detta:
- klicka på knappen "Dataanalys";
- i fönstret som öppnas, klicka på knappen "Regression";
- i fliken som visas anger du värdeintervallet för Y (antalet anställda som slutar) och för X (deras löner);
- Vi bekräftar våra åtgärder genom att trycka på "Ok"-knappen.
Som ett resultat kommer programmet automatiskt att fylla i ett nytt ark i kalkylarket med regressionsanalysdata. Notera! Excel har möjlighet att manuellt ställa in den plats du föredrar för detta ändamål. Det kan till exempel vara samma ark där Y- och X-värdena finns, eller till och med en ny arbetsbok speciellt utformad för att lagra sådan data.
Analys av regressionsresultat för R-kvadrat
I Excel ser data som erhållits under bearbetningen av data i det övervägda exemplet ut så här:
Först och främst bör du vara uppmärksam på värdet på R-kvadret. Det är bestämningskoefficienten. I det här exemplet är R-kvadrat = 0,755 (75,5 %), dvs de beräknade parametrarna för modellen förklarar sambandet mellan de övervägda parametrarna med 75,5 %. Ju högre värdet på bestämningskoefficienten är, desto mer tillämplig är den valda modellen för en viss uppgift. Man tror att den korrekt beskriver den verkliga situationen med ett R-kvadratvärde över 0,8. Om R-kvadrat<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Förhållandeanalys
Siffran 64.1428 visar vad värdet på Y blir om alla variabler xi i modellen vi överväger är nollställda. Det kan med andra ord hävdas att värdet på den analyserade parametern också påverkas av andra faktorer som inte beskrivs i en specifik modell.
Nästa koefficient -0,16285, placerad i cell B18, visar vikten av variabel Xs inflytande på Y. Detta innebär att den genomsnittliga månadslönen för anställda inom den aktuella modellen påverkar antalet avhoppare med vikten -0,16285, dvs. graden av dess inflytande överhuvudtaget liten. Tecknet "-" indikerar att koefficienten har ett negativt värde. Detta är uppenbart, eftersom alla vet att ju högre lön på företaget, desto färre uttrycker människor en önskan om att säga upp anställningsavtalet eller sluta.
Multipel regression
Denna term hänvisar till en anslutningsekvation med flera oberoende variabler av formen:
y \u003d f (x 1 + x 2 + ... x m) + ε, där y är den effektiva egenskapen (beroende variabel), och x 1 , x 2 , ... x m är faktorfaktorerna (oberoende variabler).
Parameteruppskattning
För multipel regression (MR) utförs det med metoden för minsta kvadrater (OLS). För linjära ekvationer av formen Y = a + b 1 x 1 +…+b m x m + ε, konstruerar vi ett system med normala ekvationer (se nedan)

För att förstå principen för metoden, överväg tvåfaktorsfallet. Sedan har vi en situation som beskrivs av formeln

Härifrån får vi:

där σ är variansen för motsvarande egenskap som återspeglas i indexet.
LSM är tillämplig på MP-ekvationen i en standardiserbar skala. I det här fallet får vi ekvationen:

där t y , t x 1, … t xm är standardiserade variabler för vilka medelvärdena är 0; β i är de standardiserade regressionskoefficienterna och standardavvikelsen är 1.
Observera att alla β i i detta fall är inställda som normaliserade och centraliserade, så deras jämförelse med varandra anses vara korrekt och tillåtlig. Dessutom är det vanligt att filtrera bort faktorer och kassera de med de minsta värdena på βi.
Problem med linjär regressionsekvation
Antag att det finns en tabell över prisdynamiken för en viss produkt N under de senaste 8 månaderna. Det är nödvändigt att fatta ett beslut om lämpligheten att köpa sin sats till ett pris av 1850 rubel/t.
månadsnummer | månadens namn | pris på artikel N |
|
1750 rubel per ton |
|||
1755 rubel per ton |
|||
1767 rubel per ton |
|||
1760 rubel per ton |
|||
1770 rubel per ton |
|||
1790 rubel per ton |
|||
1810 rubel per ton |
|||
1840 rubel per ton |
|||
För att lösa detta problem i Excel-kalkylarket måste du använda det dataanalysverktyg som redan är känt från exemplet ovan. Välj sedan avsnittet "Regression" och ställ in parametrarna. Man måste komma ihåg att i fältet "Input Y-intervall" måste ett värdeintervall för den beroende variabeln (i detta fall priset på en produkt under specifika månader på året) anges och i "Input" X-intervall" - för den oberoende variabeln (månadsnummer). Bekräfta åtgärden genom att klicka på "Ok". På ett nytt ark (om det var angivet så) får vi data för regression.
Baserat på dem bygger vi en linjär ekvation av formen y=ax+b, där parametrarna a och b är koefficienterna för raden med namnet på månadsnumret och koefficienterna och raden "Y-skärning" från ark med resultaten av regressionsanalysen. Således skrivs den linjära regressionsekvationen (LE) för problem 3 som:
Produktpris N = 11.714* månadsnummer + 1727.54.
eller i algebraisk notation
y = 11,714 x + 1727,54
Analys av resultat
För att avgöra om den resulterande linjära regressionsekvationen är adekvat används multipla korrelationskoefficienter (MCC) och bestämningskoefficienter, såväl som Fishers test och Students test. I Excel-tabellen med regressionsresultat visas de under namnen på multipla R, R-kvadrat, F-statistik respektive t-statistik.
KMC R gör det möjligt att bedöma stramheten i det probabilistiska sambandet mellan de oberoende och beroende variablerna. Dess höga värde indikerar ett ganska starkt samband mellan variablerna "Månadens antal" och "Pris på varor N i rubel per 1 ton". Men karaktären av detta förhållande är fortfarande okänd.
Kvadraten på bestämningskoefficienten R 2 (RI) är en numerisk egenskap av andelen av den totala spridningen och visar spridningen av vilken del av experimentdata, dvs. värden för den beroende variabeln motsvarar den linjära regressionsekvationen. I det aktuella problemet är detta värde lika med 84,8 %, dvs de statistiska data beskrivs med en hög grad av noggrannhet av den erhållna SD.
F-statistik, även kallat Fishers test, används för att bedöma signifikansen av ett linjärt samband, vilket motbevisar eller bekräftar hypotesen om dess existens.
(Elevens kriterium) hjälper till att utvärdera betydelsen av koefficienten med en okänd eller fri term för ett linjärt samband. Om värdet på t-kriteriet > t cr, så förkastas hypotesen om obetydligheten av den fria termen i den linjära ekvationen.
I det aktuella problemet för den fria medlemmen, med hjälp av Excel-verktygen, erhölls att t = 169.20903, och p = 2.89E-12, dvs. vi har en noll sannolikhet att den korrekta hypotesen om den fria medlemmens obetydlighet kommer att avvisas. För koefficienten vid okänd t=5,79405 och p=0,001158. Sannolikheten för att den korrekta hypotesen om koefficientens insignifikans för det okända kommer att förkastas är med andra ord 0,12 %.
Således kan det hävdas att den resulterande linjära regressionsekvationen är adekvat.
Problemet med det ändamålsenliga med att köpa ett aktieblock
Multipel regression i Excel utförs med samma dataanalysverktyg. Tänk på ett specifikt tillämpat problem.
NNN:s ledning måste fatta ett beslut om lämpligheten av att köpa en andel på 20 % i MMM SA. Kostnaden för paketet (JV) är 70 miljoner US-dollar. NNN-specialister samlade in data om liknande transaktioner. Det beslutades att utvärdera värdet av aktieblocket enligt sådana parametrar, uttryckt i miljoner US-dollar, som:
- leverantörsreskontra (VK);
- årlig omsättning (VO);
- kundfordringar (VD);
- kostnad för anläggningstillgångar (SOF).
Dessutom används parametern löneskulder för företaget (V3 P) i tusentals US-dollar.
Lösning med hjälp av Excel-kalkylblad
Först och främst måste du skapa en tabell med initiala data. Det ser ut så här:

- anropa fönstret "Dataanalys";
- välj avsnittet "Regression";
- i rutan "Inmatningsintervall Y" anger du värdeintervallet för beroende variabler från kolumn G;
- klicka på ikonen med en röd pil till höger om fönstret "Inmatningsintervall X" och välj intervallet för alla värden från kolumnerna B, C, D, F på arket.
Välj "Nytt arbetsblad" och klicka på "Ok".
Få regressionsanalysen för det givna problemet.

Granskning av resultat och slutsatser
"Vi samlar in" från de avrundade data som presenteras ovan på Excel-kalkylarket, regressionsekvationen:
SP \u003d 0,103 * SOF + 0,541 * VO - 0,031 * VK + 0,405 * VD + 0,691 * VZP - 265,844.
I en mer bekant matematisk form kan det skrivas som:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Data för JSC "MMM" presenteras i tabellen:
Genom att ersätta dem i regressionsekvationen får de en siffra på 64,72 miljoner US-dollar. Detta innebär att aktierna i JSC MMM inte bör köpas, eftersom deras värde på 70 miljoner US-dollar är ganska överskattat.
Som du kan se gjorde användningen av Excel-kalkylbladet och regressionsekvationen det möjligt att fatta ett välgrundat beslut om genomförbarheten av en mycket specifik transaktion.
Nu vet du vad regression är. Exemplen i Excel som diskuterats ovan hjälper dig att lösa praktiska problem från ekonometriområdet.
Regressionsanalys— En metod för att modellera uppmätta data och studera deras egenskaper. Data består av värdepar beroende variabel(svarsvariabel) och oberoende variabel(förklarande variabel). Regressionsmodellen är en funktion av den oberoende variabeln och parametrar med en tillagd slumpvariabel. Modellparametrarna är avstämda på ett sådant sätt att modellen approximerar data på bästa möjliga sätt. Approximationskvalitetskriteriet (objektiv funktion) är vanligtvis medelkvadratfelet: summan av kvadraterna av skillnaden mellan modellens värden och den beroende variabeln för alla värden av den oberoende variabeln som ett argument. Regressionsanalys är en gren av matematisk statistik och maskininlärning. Det antas att den beroende variabeln är summan av värdena för någon modell och en slumpvariabel. Beträffande arten av fördelningen av detta värde görs antaganden, kallade datagenereringshypotesen. För att bekräfta eller motbevisa denna hypotes utförs statistiska tester, så kallade restanalyser. Detta förutsätter att den oberoende variabeln inte innehåller fel. Regressionsanalys används för prognostisering, tidsserieanalys, hypotestestning och för att upptäcka dolda samband i data.
Definition av regressionsanalys
Provet kanske inte är en funktion, utan en relation. Till exempel kan data för att bygga en regression vara: . I ett sådant urval motsvarar ett värde av variabeln flera värden på variabeln.
Linjär regression
Linjär regression förutsätter att funktionen beror linjärt på parametrarna. I det här fallet är ett linjärt beroende av den fria variabeln valfritt,
I det fall där den linjära regressionsfunktionen har formen
här är komponenterna i vektorn.
Parametervärdena vid linjär regression hittas med minsta kvadratmetoden. Användningen av denna metod motiveras av antagandet om en gaussisk fördelning av en slumpvariabel.
Skillnaderna mellan de faktiska värdena för den beroende variabeln och de rekonstruerade kallas regressionsrester(rester). Synonymer används också i litteraturen: rester Och misstag. En av de viktiga uppskattningarna av kvalitetskriteriet för det erhållna beroendet är summan av kvadraterna av residualerna:
Här - Summan av kvadratiska fel.
Variansen av residualerna beräknas med formeln
Här - Mean Square Error, Mean Square Error, Mean Square Error.
|
|
|


Graferna visar prov markerade med blå punkter och regressionsberoenden markerade med heldragna linjer. Abskissan visar den fria variabeln och ordinatan visar den beroende variabeln. Alla tre beroenden är linjära med avseende på parametrarna.
Icke-linjär regression
Icke-linjära regressionsmodeller - Visa modeller
som inte kan representeras som en prickprodukt
var är parametrarna för regressionsmodellen, är en fri variabel från utrymmet, är den beroende variabeln, är en slumpvariabel och är en funktion från någon given uppsättning.
Parametervärden i fallet med icke-linjär regression hittas med en av metoderna för gradientnedstigning, till exempel Levenberg-Marquardt-algoritmen.
Om villkor
Termen "regression" myntades av Francis Galton i slutet av 1800-talet. Galton fann att barn till långa eller korta föräldrar vanligtvis inte ärver enastående längd och kallade detta fenomen för "regression till medelmåttighet". Till en början användes termen uteslutande i biologisk mening. Efter Karl Pearsons arbete började denna term användas i statistik.
I den statistiska litteraturen skiljer man på regression som involverar en fri variabel och med flera fria variabler − en-dimensionell Och flerdimensionell regression. Det antas att vi använder flera fria variabler, det vill säga den fria variabeln är en vektor. I speciella fall, när den fria variabeln är en skalär, kommer den att betecknas med . Skilja på linjär Och icke-linjär regression. Om regressionsmodellen inte är en linjär kombination av funktioner av parametrar, så talar man om en icke-linjär regression. I det här fallet kan modellen vara en godtycklig överlagring av funktioner från en viss uppsättning. Icke-linjära modeller är exponentiella, trigonometriska och andra (till exempel radiella basfunktioner eller Rosenblatt-perceptronen), som antar att förhållandet mellan parametrarna och den beroende variabeln är icke-linjärt.
Skilja på parametrisk Och icke-parametrisk regression. Det är svårt att dra en skarp gräns mellan dessa två typer av regressioner. För närvarande finns det inget allmänt accepterat kriterium för att skilja en typ av modell från en annan. Till exempel anses linjära modeller vara parametriska, medan modeller som inkluderar medelvärdesberäkning av den beroende variabeln över utrymmet för den fria variabeln anses vara icke-parametriska. Ett exempel på en parametrisk regressionsmodell: linjär prediktor, flerskiktsperceptron. Blandad regressionsmodell Exempel: Radiella basfunktioner. Icke-parametrisk modell - glidande medelvärde i ett fönster med viss bredd. I allmänhet skiljer sig icke-parametrisk regression från parametrisk regression genom att den beroende variabeln inte beror på ett värde av den fria variabeln, utan på någon given grannskap av detta värde.
Det finns en skillnad mellan termerna: "funktionsapproximation", "approximation", "interpolation" och "regression". Den består av följande.
Approximation av funktioner. En funktion av ett diskret eller kontinuerligt argument ges. Det krävs att man hittar en funktion från någon parametrisk familj, till exempel bland algebraiska polynom av en given grad. Funktionsparametrar måste leverera ett minimum av viss funktionalitet, t.ex.
Termin approximationär en synonym för termen "approximation av funktioner". Det används oftare när det gäller en given funktion, som en funktion av ett diskret argument. Här krävs också att man hittar en sådan funktion som passerar närmast alla punkter i den givna funktionen. Detta introducerar konceptet resterär avstånden mellan punkterna i en kontinuerlig funktion och motsvarande punkter i funktionen för ett diskret argument.
Interpolation funktioner är ett specialfall av approximationsproblemet, när det krävs att vid vissa punkter, kallas interpolationsnoder funktionens värden och funktionen som approximerar den sammanföll. I ett mer allmänt fall läggs restriktioner på värdet på vissa derivat av derivat. Det vill säga givet en funktion av ett diskret argument. Det krävs att man hittar en funktion som går igenom alla punkter. I det här fallet används vanligtvis inte måtten, men begreppet "jämnhet" för den önskade funktionen introduceras ofta.
I närvaro av en korrelation mellan faktor och resulterande tecken måste läkare ofta bestämma med vilken mängd värdet på ett tecken kan ändras när ett annat ändras med en måttenhet som allmänt accepteras eller fastställts av forskaren själv.
Hur kommer till exempel kroppsvikten för skolbarn i 1:a klass (flickor eller pojkar) att förändras om deras längd ökar med 1 cm. För detta ändamål används regressionsanalysmetoden.
Oftast används regressionsanalysmetoden för att ta fram normativa skalor och standarder för fysisk utveckling.
- Definition av regression. Regression är en funktion som gör det möjligt, baserat på medelvärdet för ett attribut, att bestämma medelvärdet för ett annat attribut som är korrelerat med det första.
För detta ändamål används regressionskoefficienten och ett antal andra parametrar. Till exempel kan du beräkna antalet förkylningar i genomsnitt vid vissa värden av den genomsnittliga månatliga lufttemperaturen under höst-vinterperioden.
- Definition av regressionskoefficienten. Regressionskoefficienten är det absoluta värde med vilket värdet av ett attribut ändras i genomsnitt när ett annat attribut som är associerat med det ändras med en specificerad måttenhet.
- Formel för regressionskoefficient. R y / x \u003d r xy x (σ y / σ x)
där R y / x - regressionskoefficient;
r xy - korrelationskoefficient mellan egenskaperna x och y;
(σ y och σ x) - standardavvikelser för egenskaperna x och y.I vårt exempel;
σ x = 4,6 (standardavvikelse för lufttemperatur under höst-vinterperioden;
σ y = 8,65 (standardavvikelse för antalet smittsamma förkylningar).
Således är R y/x regressionskoefficienten.
R y / x \u003d -0,96 x (4,6 / 8,65) \u003d 1,8, d.v.s. med en minskning av den genomsnittliga månatliga lufttemperaturen (x) med 1 grad, kommer det genomsnittliga antalet smittsamma förkylningar (y) under höst-vinterperioden att förändras med 1,8 fall. - Regressions ekvation. y \u003d M y + R y / x (x - M x)
där y är medelvärdet för attributet, vilket bör bestämmas när medelvärdet för ett annat attribut (x) ändras;
x - känt medelvärde för en annan egenskap;
R y/x - regressionskoefficient;
M x, M y - kända medelvärden för funktionerna x och y.Till exempel kan medelantalet smittsamma förkylningar (y) bestämmas utan speciella mätningar vid vilket medelvärde som helst av den genomsnittliga månatliga lufttemperaturen (x). Så, om x \u003d - 9 °, R y / x \u003d 1,8 sjukdomar, M x \u003d -7 °, M y \u003d 20 sjukdomar, då y \u003d 20 + 1,8 x (9-7) \u003d 20 + 3,6 = 23,6 sjukdomar.
Denna ekvation tillämpas i fallet med ett rätlinjigt förhållande mellan två egenskaper (x och y). - Syftet med regressionsekvationen. Regressionsekvationen används för att plotta regressionslinjen. Den senare tillåter, utan speciella mätningar, att bestämma vilket medelvärde som helst (y) för ett attribut, om värdet (x) för ett annat attribut ändras. Baserat på dessa data byggs en graf - regressionslinje, som kan användas för att bestämma det genomsnittliga antalet förkylningar vid vilket värde som helst av den genomsnittliga månadstemperaturen inom intervallet mellan de beräknade värdena för antalet förkylningar.
- Regression sigma (formel).
där σ Ru/x - sigma (standardavvikelse) för regressionen;
σ y är standardavvikelsen för egenskapen y;
r xy - korrelationskoefficient mellan egenskaperna x och y.Så, om σ y är standardavvikelsen för antalet förkylningar = 8,65; r xy - korrelationskoefficienten mellan antalet förkylningar (y) och den genomsnittliga månatliga lufttemperaturen under höst-vinterperioden (x) är - 0,96, då

- Syftet med sigma-regression. Ger en egenskap för måttet på mångfalden av den resulterande egenskapen (y).
Till exempel kännetecknar det mångfalden av antalet förkylningar vid ett visst värde av den genomsnittliga månatliga lufttemperaturen under höst-vinterperioden. Så det genomsnittliga antalet förkylningar vid lufttemperatur x 1 \u003d -6 ° kan variera från 15,78 sjukdomar till 20,62 sjukdomar.
Vid x 2 = -9° kan det genomsnittliga antalet förkylningar variera från 21,18 sjukdomar till 26,02 sjukdomar osv.Regressionssigma används i konstruktionen av en regressionsskala, som återspeglar avvikelsen mellan värdena för det effektiva attributet från dess medelvärde som plottas på regressionslinjen.
- Data som krävs för att beräkna och plotta regressionsskalan
- regressionskoefficient - Ry/x;
- regressionsekvation - y \u003d M y + R y / x (x-M x);
- regression sigma - σ Rx/y
- Beräkningssekvensen och grafisk representation av regressionsskalan.
- bestäm regressionskoefficienten med formeln (se punkt 3). Till exempel bör man bestämma hur mycket kroppsvikten kommer att förändras i genomsnitt (vid en viss ålder beroende på kön) om medelhöjden ändras med 1 cm.
- enligt formeln för regressionsekvationen (se punkt 4), bestäm vad som blir medelvärdet, till exempel kroppsvikten (y, y 2, y 3 ...) * för ett visst tillväxtvärde (x, x 2, x 3 ...).
________________
* Värdet på "y" bör beräknas för minst tre kända värden på "x".Samtidigt är medelvärdena för kroppsvikt och längd (M x och M y) för en viss ålder och kön kända
- beräkna sigma för regressionen, känna till motsvarande värden för σ y och r xy och ersätta deras värden i formeln (se punkt 6).
- baserat på de kända värdena x 1, x 2, x 3 och deras motsvarande medelvärden y 1, y 2 y 3, såväl som de minsta (y - σ ru / x) och största (y + σ ru / x) värden\u200b\u200b(y) konstruerar en regressionsskala.
För en grafisk representation av regressionsskalan markeras först värdena x, x 2 , x 3 (y-axeln) på grafen, dvs. en regressionslinje byggs, till exempel kroppsviktens (y) beroende av längden (x).
Sedan, vid motsvarande punkter y 1 , y 2 , y 3 är de numeriska värdena för regressionssigma markerade, dvs. på grafen hitta de minsta och största värdena av y 1 , y 2 , y 3 .
- Praktisk användning av regressionsskalan. Normativa skalor och standarder utvecklas, särskilt för fysisk utveckling. Enligt standardskalan är det möjligt att ge en individuell bedömning av barns utveckling. Samtidigt bedöms den fysiska utvecklingen som harmonisk om till exempel vid en viss höjd barnets kroppsvikt är inom ett sigma av regression till den genomsnittliga beräknade kroppsviktsenheten - (y) för en given längd (x) (y ± 1 σ Ry/x).
Fysisk utveckling anses disharmonisk vad gäller kroppsvikt om barnets kroppsvikt för en viss längd ligger inom den andra regressionen sigma: (y ± 2 σ Ry/x)
Den fysiska utvecklingen kommer att vara kraftigt disharmonisk både på grund av överskott och otillräcklig kroppsvikt om kroppsvikten för en viss höjd ligger inom regressionens tredje sigma (y ± 3 σ Ry/x).
Enligt resultaten av en statistisk studie av den fysiska utvecklingen av 5-åriga pojkar är det känt att deras genomsnittliga höjd (x) är 109 cm och deras genomsnittliga kroppsvikt (y) är 19 kg. Korrelationskoefficienten mellan längd och kroppsvikt är +0,9, standardavvikelser presenteras i tabellen.
Nödvändig:
- beräkna regressionskoefficienten;
- med hjälp av regressionsekvationen, bestäm vad den förväntade kroppsvikten för 5-åriga pojkar kommer att vara med en höjd lika med x1 = 100 cm, x2 = 110 cm, x3 = 120 cm;
- beräkna regressionssigma, bygga en regressionsskala, presentera resultaten av dess lösning grafiskt;
- dra lämpliga slutsatser.
Tillståndet för problemet och resultaten av dess lösning presenteras i den sammanfattande tabellen.
bord 1
| Villkor för problemet | Resultat av problemlösning | ||||||||
| regressions ekvation | sigma regression | regressionsskala (förväntad kroppsvikt (i kg)) | |||||||
| M | σ | r xy | R y/x | X | På | σRx/y | y - σ Rу/х | y + σ Rу/х | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Höjd (x) | 109 cm | ± 4,4 cm | +0,9 | 0,16 | 100 cm | 17,56 kg | ± 0,35 kg | 17,21 kg | 17,91 kg |
| Kroppsvikt (y) | 19 kg | ± 0,8 kg | 110 cm | 19,16 kg | 18,81 kg | 19,51 kg | |||
| 120 cm | 20,76 kg | 20,41 kg | 21,11 kg | ||||||
Lösning.
Produktion. Således tillåter regressionsskalan inom de beräknade värdena för kroppsvikt dig att bestämma den för något annat värde av tillväxt eller att bedöma barnets individuella utveckling. För att göra detta, återställ vinkelrät mot regressionslinjen.
- Vlasov V.V. Epidemiologi. - M.: GEOTAR-MED, 2004. - 464 sid.
- Lisitsyn Yu.P. Folkhälsa och sjukvård. Lärobok för gymnasieskolor. - M.: GEOTAR-MED, 2007. - 512 sid.
- Medik V.A., Yuriev V.K. En föreläsningskurs om folkhälsa och hälso- och sjukvård: Del 1. Folkhälsa. - M.: Medicin, 2003. - 368 sid.
- Minyaev V.A., Vishnyakov N.I. m.fl. Socialmedicin och hälsovårdsorganisation (Guide i 2 volymer). - St Petersburg, 1998. -528 sid.
- Kucherenko V.Z., Agarkov N.M. Social hygien och organisation av hälso- och sjukvård (Tutorial) - Moskva, 2000. - 432 s.
- S. Glantz. Medikobiologisk statistik. Per från engelska. - M., Practice, 1998. - 459 sid.
 Anna Vyrubova, kejsarinnans närmaste vän Vad sa hennes samtida om Anna Vyrubova
Anna Vyrubova, kejsarinnans närmaste vän Vad sa hennes samtida om Anna Vyrubova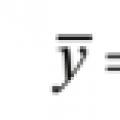 Regressionsanalys - en statistisk metod för att studera en stokastisk variabels beroende av variabler
Regressionsanalys - en statistisk metod för att studera en stokastisk variabels beroende av variabler Myter om kavalleriet Wehrmacht överlevde tack vare Stalin
Myter om kavalleriet Wehrmacht överlevde tack vare Stalin